Apache NiFi: Trattare i dati in maniera scalabile

INTRODUZIONE
Negli ultimi anni è sempre più evidente che i "dati" memorizzati all'interno dei vari database aziendali sono una risorsa che, se sfruttati nella giusta maniera, possono portare una ricchezza inaspettata.Grazie a questo sono nate negli ultimi anni figure professionali nuove come Big Data Analytics Specialist, Big Data Architect, Data Scientist e Chief Data Officer
Tutti queste figure aiutano a capire come sfruttare i dati, aggregarli e ottimizzarli
Esistono vari tool in grado di aiutare a reperire, trasformare e salvare i dati, oggi mi voglio concentrare su uno strumento utile completo e open-source.
APACHE NIFI
Come scritto sul sito ufficiale Apache NiFi è un sistema facile da usare, potente e affidabile per elaborare e distribuire i dati.INSTALLAZIONE
Installare il tool è molto semplice, occorre scaricare il package dalla pagina download del sito ufficiale e scompattarlo all'interno di una cartella.Per avviarlo occorre entrare nella cartella bin ed eseguire il giusto eseguibili:
- windows: run-nifi.bat
- linux / unix: sh nifi.sh start
Apache NiFi è un'applicazione web-based quindi occorre aprire il browser all'indirizzo
http://localhost:8080/nifi
FRONTEND
All'apertura della pagina verrà visualizzata una griglia vuota con:
- tool bar
- status bar
- palette di controllo

All'interno di Apache Nifi occorre avere familiarità dei seguenti termini:
- FlowFile: E' un file che raggruppa l'insieme di dati inseriti nel software. A sua volta può essere suddiviso in:
- Attributes (chiave valore)
- Content
- Processor: E' un componente distinto a forma di blocco all'interno della griglia. Un processor può creare, inviare, trasformare, splittare, mergiare FlowFile.
Quando si vuole inserire un nuovo processor in griglia viene visualizzata una finestra molto completa dove potrete visionare tutta la serie di processor che si possono utilizzare. Nello screen ho filtrato quelli per interagire con un sistema SQL
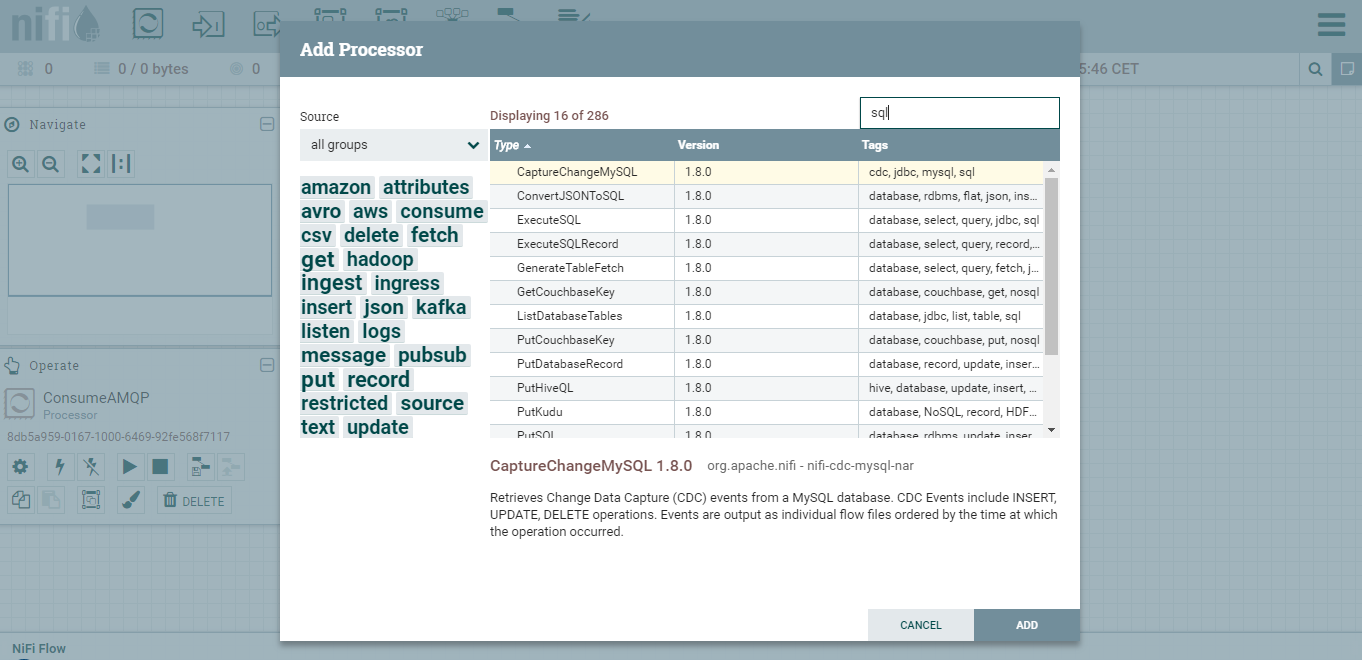
Come detto precedentemente ogni processor è visualizzato nella griglia come un blocco, all'interno vi sono presenti informazioni e statistiche

PROCESSOR
Il tool include una serie molto completa di processor, di seguito una lista di componenti per funzionalità
Data Trasformation
Per conversioni vari tra formati XML, JSON, XSLT , Regular Expression, Encrypt, Decrypt
Routing e Mediation
Per Monitorare, controllare, bilanciare il carico di lavoro
Database Access
Per interrogare e reperire dati da vari database
Data Ingestion / Sending Data
Reperimento ed invio dati da sorgenti vari come HTTP, TCP, UDP, FTP, JMS, HDFS, S3, Mongo, Kafka, Twitter
Splitting e Aggregation
Varie utility per splittare e aggregare i dati entranti nel sistema
AWS
Interazione custom per Amazon Web Services
Di seguito i due tutorial ufficiali che vi faranno capire meglio la potenza di questo strumento
Alla prossima
PARTE 1
PARTE 2

Casinos Near Me - MapYRO
RispondiEliminaWith 정읍 출장샵 over 1,200 slots and more than 2,500 table 파주 출장안마 games and live 경기도 출장마사지 casino games, there's something for everyone to 안양 출장샵 enjoy. Find your favorite game at any 군산 출장샵 of the