Cosa sono i Graph Databases?
INTRODUZIONE
Tipicamente quando pensiamo alla parola database viene subito in mente la famosa struttura tabellare, con le colonne che descrivono gli attributi e le righe che associano gli attributi con i corrispondenti valori.
Comunemente, nel caso in cui ho più tabelle posso legarle mettendole in relazione tra di loro.
Questo che ho descritto, in maniera semplificata, è il concetto base di un database relazionale.
Questo che ho descritto, in maniera semplificata, è il concetto base di un database relazionale.

Una volta che ho scritto i dati serve un modo per recuperarli. Grazie al linguaggio SQL è possibile utilizzare dei costrutti per filtrare o selezionare dati all'interno di una o più tabelle.
Utilizzando un approccio No SQL (query first) ogni tabella raffigura il dato de-normalizzato come verrebbe visualizzato in un ipotetico front-end.
Ipotizzando di analizzare e sviluppare una problematica abbastanza complessa, la soluzione in un relazionale potrebbe raggiungere un numero non importante di tabelle alcune relazionate tra di loro.
Se volessimo sviluppare lo stesso scenario con un No SQL dovremmo aggiungere un fattore moltiplicativo perchè il numero delle tabelle deve rispecchiare il come vengono reperiti i dati dall'applicazione.
Quando i numeri da gestire diventano importanti, l'approccio No SQL permette di avere dei risolvi positivi in termini di prestazioni ma nello stesso tempo potrebbe risultare molto complesso modificare l'intera struttura a seguito di un cambio di design.
Inversa la cosa se utilizzo un relazionale, molto più facile un cambio di modello ma ne risentirebbe in termini di prestazioni.
GRAPH DATABASES
Un'alternativa all'approccio relazionale e a quello No SQL sono i Graph Databases (database a grafi)
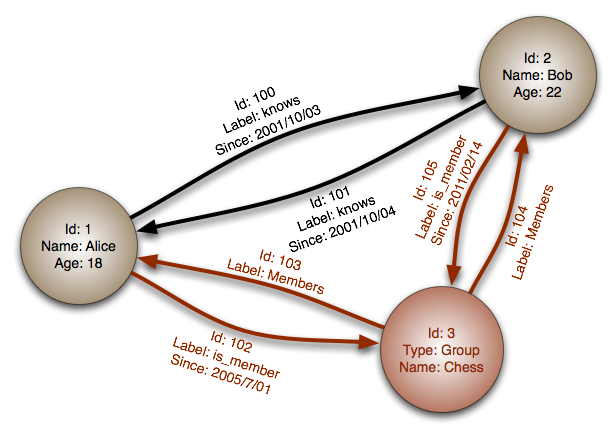
Un grafo è una configurazione formata da un insieme di punti ( vertici o nodi ) e un insieme di linee ( archi ) che uniscono coppie di nodi.
Come da definizione, una struttura a Grafo ha dei concetti diversi che dobbiamo andare ad analizzare singolarmente:
- Vertex (Vertice), descrive una cosa (per esempio attore o film)
- Può avere degli attributi che ne arricchiscono la descrizione
- Edge (Bordo), è una relazione tra due Vertex con una label e può:
- avere degli attributi che ne arricchiscono la descrizione
- avere una direzione
- collegare più Edge

oppure

VANTAGGI?
Fruttando i database a grafi ho i seguenti vantaggi:
- Non devo creare delle strutture (Tabelle) con uno schema rigido
- Non devo esplicitamente dichiarare le relazioni, per esempio in determinati Vertex possono averle in altri no!
- Posso dichiarare relazioni complesse e molteplici
- Aggiungere nuovi Edge è un lavoro facile e immediato
Inoltre con delle semplici query è possibile recuperare sia le informazioni riguardo gli Edge che riguardo ai Vertex.
Di seguito un esempio preso dalle slide di DataStax

CONCLUSIONI
I database a grafi sono utilissimi quando occorre un sistema basato sul reperimento delle informazioni attraverso le (molte) relazioni tra entità.
Dei casi tipici di utilizzo sono social network, motori di raccomandazioni e rilevamento di frodi o, in generale, in tutti quei casi d'uso dove è necessario creare molte relazioni tra dati ed eseguire rapidamente query su di esse.
Tra i link che trovate sotto, segnalo Titan uno strumento che permette di costruire dei sistemi distribuiti e scalabili associando come layer storage Apache Cassandra, Apache HBase, Oracle BerkleyDB e come layer analytics strumenti come Apache Spark, Apache Hadoop e Apache Giraph.

Commenti
Posta un commento